
/toc
目标类别较少时,直接用标准的softmax公式进行计算没问题,当目标类别特别多时,则需采用估算近似的方法简化softmax中归一化的计算。
$h_{\theta}\left( x^{\left( i \right)} \right) =\left[ \begin{array}{c} p\left( y^{\left( i \right)}=1\left| x^{\left( i \right)} \right. \right)\\ p\left( y^{\left( i \right)}=2\left| x^{\left( i \right)} \right. \right)\\ \vdots\\ p\left( y^{\left( i \right)}=k\left| x^{\left( i \right)} \right. \right)\\ \end{array} \right] =\frac{1}{\sum_{j=1}^k{e^{\theta _{j}^{T}x^{\left( i \right)}}}}\left[ \begin{array}{c} e^{\theta _{1}^{T}x^{\left( i \right)}}\\ e^{\theta _{2}^{T}x^{\left( i \right)}}\\ \vdots\\ e^{\theta _{k}^{T}x^{\left( i \right)}}\\ \end{array} \right]$
由上述softmax的假设函数可知,在学习阶段,每进行一个样本的类别估计都需要计算其属于各个类别的得分并归一化为概率值。当类别数特别大时,如语言模型中从海量词表中预测下一个词(词表中词即这里的类别)。用标准的softmax进行预测就会出现瓶颈。
NCENCE是基于采样的方法,将多分类问题转为二分类问题。以语言模型为例,利用NCENCE可将从词表中预测某个词的多分类问题,转为从噪音词中区分出目标词的二分类问题。具体如图所示:
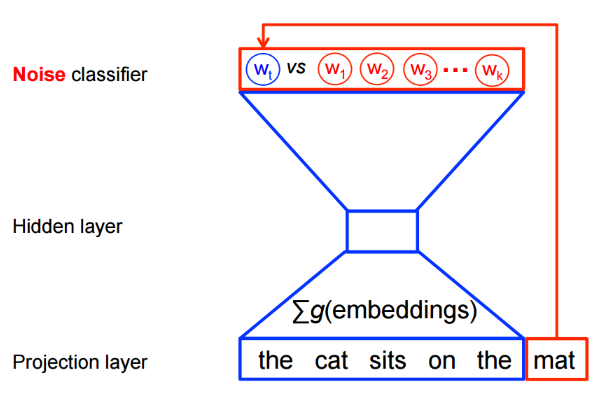
下面从数学角度看看具体如何构造转化后的目标函数(损失函数)
记词wiwi的上下文为cici,~wij(j=1,2,⋯,k)w~ij(j=1,2,⋯,k)为从某种噪音分布QQ中生成的kk个噪音词(从词表中采样生成)。则(ci,wi)(ci,wi)构成了正样本(y=1y=1),(ci,~wij)(ci,w~ij)构成了负样本(y=0y=0)。
基于上述描述,可用逻辑回归模型构造如下损失函数
$Jθ=−∑wi∈V[logP(y=1|ci,wi)+k∑j=1logP(y=0|ci,~wij)]$
$Jθ=−∑wi∈V[logP(y=1|ci,wi)+∑j=1klogP(y=0|ci,w~ij)]$
上述损失函数中共有k+1k+1个样本。可看成从两种不同的分布中分别采样得到的,一个是依据训练集的经验分布PtrainPtrain每次从词表中采样一个目标样本,其依赖于上下文cc;而另一个是依据噪音分布QQ每次从词表中采样kk个噪音样本(不包括目标样本)。基于上述两种分布,有如下混合分布时的采样概率:
P(y,w|c)=1k+1Ptrain(w|c)+kk+1Q(w)
P(y,w|c)=1k+1Ptrain(w|c)+kk+1Q(w)
更进一步地,有
P(y=1|w,c)=1k+1Ptrain(w|c)1k+1Ptrain(w|c)+kk+1Q(w)=Ptrain(w|c)Ptrain(w|c)+kQ(w)
P(y=1|w,c)=1k+1Ptrain(w|c)1k+1Ptrain(w|c)+kk+1Q(w)=Ptrain(w|c)Ptrain(w|c)+kQ(w)